Understanding AI’s Impact on Copyright and Privacy
Generative AI is revolutionizing the way we create, understand, and interact with content. From creating images in seconds to generating human-like text (mostly), AI systems like DeepSeek and Stable Diffusion are constantly innovating.
But as these technologies evolve, they’re also dragging with themselves new copyright and privacy legal problems. While the EU has introduced a range of AI guidelines to tackle these issues, finding middle ground remains challenging when cases involve a complex of legal frameworks.
So, what happens when AI models learn from digital work without asking permission? And how do regulators keep up with these rapid changes?
In this article, we look into how AI gathers data, the deepening copyright and privacy concerns, and the real-world legal challenges.
When Generative AI, Copyright, and Privacy Meet
AI is not only transforming our creative process but is also sparking urgent debates over who controls content, where does copyright stand and how is user privacy protected.
Let’s break down what’s happening lately and why it matters.
How AI Learns from the Web
Lets imagine the internet as one giant library. To build smart AI systems, companies collect huge amounts of information from this library - a process called web scraping.
This means they use computer programs to automatically gather data from countless websites. Then, the collected data teaches AI systems how to create text, images, and more.
Many argue that using public information in this way is needed to drive innovation. Interested companies say that by learning from data already available online, AI can help improve customer service, support scientific research, and even help with creative tasks.
But this method isn’t without its problems. Collecting data from everywhere also means that personal information might sometimes be involved, which raises concerns about privacy.
For example, OpenAI defends its approach by highlighting that its training process relies on data gathered under a “legitimate interest”.
According to this point of view, the benefits of powering innovative AI systems outweigh the risks posed by processing personal data, as long as the sources of information are public.
Copyright and Privacy: What’s at Stake?
Not everyone supports the idea of AI massively scraping the Internet for everything it finds. Some worry that by freely taking and processing information, AI might be stepping on the rights of creators who worked hard to produce original content. If an AI uses someone’s image or article without proper permission, it could weaken the protections that copyright laws are supposed to offer.
There’s also a privacy angle to consider. If restrictions are placed on the way AI collects data due to copyright issues, companies might turn to other sources that could contain even more personal details. This switch could open up a whole new set of privacy problems. In other words, how we allow AI to be trained has a direct impact on how much respect we give to both creative work and individual privacy.
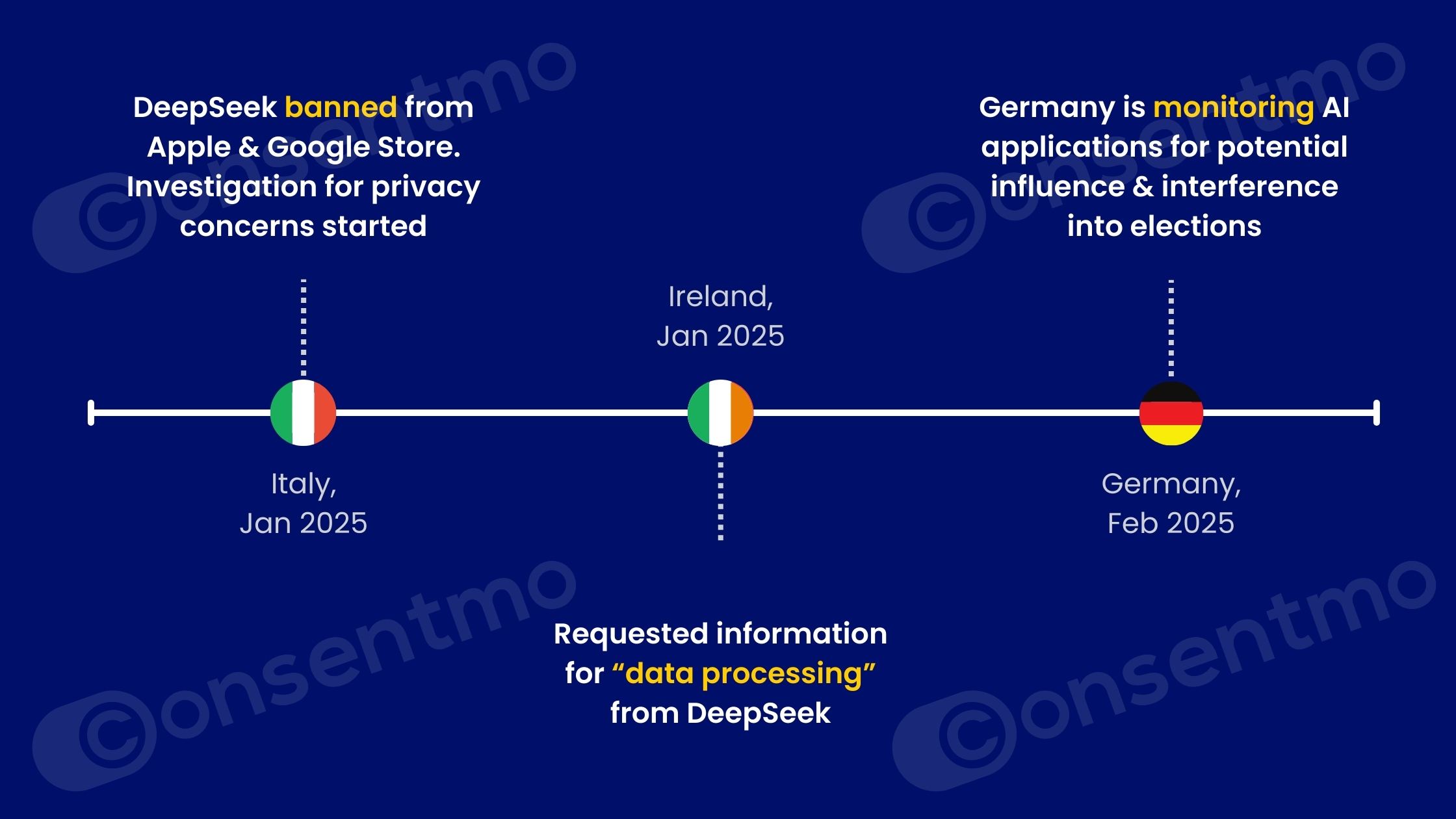
A recent example is seen in Germany where regulators have decided to control AI tools like DeepSeek. The Chinese AI startup has attracted attention due to concerns over data handling during sensitive times, like election periods:
"Of course, the security authorities are concerned with AI applications and possible manipulation, possible influence on the formation of public opinion through AI applications, especially now in view of the elections," a spokesperson said, although without naming any specific AI models.
It seems governments are keeping a close eye as AI technology grows more powerful, especially as it can have a direct social impact.
AI and Copyright: EU Laws Explained
The European Union does have strong copyright in place but once AI is mixed into it… Things seem to be taking a turn of their own.
What Does EU Law Say?
Under EU law, copyright has its own place in AI governance. The EU AI Act, for example, informs companies that to create general-purpose AI models they must have policies in place to follow EU copyright and related rights. This includes having the technology to track and respect any reservations of rights set out in Directive (EU) 2019/790. Simply said - if an AI company is building a model that learns from data online, they have to pay close attention to copyright issues and follow the legal guidelines.
This EU AI Act is meant to help keep the interests of content creators in mind while still allowing companies to innovate.
However, there are some tricky areas to navigate. The guidelines are clear on what companies should do, but in practice, applying these rules is not easy at all.
Real-Life Challenges: The Case of Robert Kneschke
Robert Kneschke is a photographer who brought a lawsuit against an AI organization called LAION for using his images without permission to train their AI.
The Hamburg Regional Court ruled that LAION’s actions fell under an exception in German copyright law for text and data mining meant for “scientific research”. This decision means the usual reservation of rights can be ignored. In effect, the ruling left some uncertainty about how much protection creators actually have in similar cases in the future.
The outcome has sparked a discussion.
What Happened: The court dismissed the case, saying the AI’s use of his photos fell under an exception for “text and data mining.”
The Problem: A lot of questions unanswered. If AI companies can use copyrighted material under this exception, how much protection do creators really have?
This case shows how hard it is to apply copyright laws to AI. The rules are still evolving, and creators are worried their work might be used without proper credit or compensation.

What’s Next for AI and Copyright in the EU?
The EU’s laws are a good start, but there’s still a lot to figure out. Lawmakers and tech companies need to work together to create clearer rules and better ways to protect creators.
Possible Solutions:
- Clearer licensing agreements for AI training data.
- Better tools for creators to opt out of having their work used in AI training.
- Make sure AI keeps evolving without leaving creators behind.
What Does This Mean for AI Like DeepSeek?
As an AI model, DeepSeek is part of this evolving conversation about copyright and AI. So, we decided to ask it directly how it follows copyright and privacy guidelines.
Here is what it had to say:
- I’m trained on publicly available data, but my developers take care to follow legal and ethical standards.
- If you use me to generate content, it’s important to add your own creative touch to avoid copyright issues.
- AI models like DeepSeek (me!) are part of the solution, not the problem. By following rules like those in the EU AI Act, we can help create a future where AI and creators work together, not against each other.
However, reality lately has been much different for the AI model.
As mentioned, Germany is actively scrutinizing AI applications, with authorities paying special attention to how these systems handle bias and whether they can deliver fair and equitable outcomes.
In Italy, DeepSeek has been banned from both the Apple and Google Stores until it can provide detailed answers about what personal data is collected, where that data comes from, why it is used, and whether any of it is stored in China.
Meanwhile, Ireland has requested comprehensive information from DeepSeek regarding its data processing practices, focusing on the impact these practices have on data subjects within the country.
Getty Images vs. Stability AI: A Landmark Copyright Dispute
The battle between Getty Images and Stability AI has become one of the most talked-about legal cases in the digital world. At its core, the case is about how traditional copyright laws can be applied to modern AI practices, especially when it comes to how AI systems learn from existing images online.
What's the case about?
A group of copyright holders, including stock image giant Getty Images and other companies, filed a lawsuit against Stability AI, an open-source AI company based in the UK. They claim that Stability AI used images from the Getty Images websites without permission to train its AI model, Stable Diffusion.
Stability AI admitted that "at least some images" were used in the training process, but they didn’t specify which ones. The claimants argue that this unauthorized use is a direct copyright infringement, as well as secondary infringement by importing pre-trained software into the UK. They also argue that the AI-generated images reproduce significant parts of the original works.
An interesting twist in the case is the attempt to bring a representative claim on behalf of over 50,000 copyright owners who have exclusive licenses with Getty Images. This would have allowed one claimant (the so-called “Sixth Claimant”) to represent a huge group of artists at the same time.
However, the defendant argued that because each copyright owner might have different agreements and levels of protection, each claim should be looked at individually.
How the Court Decided
When the court looked into the case, one major challenge was the lack of a clear list showing exactly which copyrighted images were used to train Stable Diffusion. Without that list, it was impossible to decide for each individual copyright owner whether they should be part of the representative claim.
Because of this, the court chose not to let the case move forward.
This decision highlights the difficulty of handling massive copyright claims in the era of big data and AI. It points to the absolute need for more organized legal methods that can deal with such large-scale disputes.
Why This Case is a Big Deal
This lawsuit isn’t just between two companies. The outcome will be a major reference point for all AI copyright disputes from now on.
The Representation Problem: One claimant tried to represent over 50,000 copyright owners in a single lawsuit. However, the court declined, because it was too hard to prove which specific images were used, how, and to what extent a copyright infringement was made.
The Bigger Issue: This case shows how outdated copyright laws struggle to handle mass digital claims. When AI trains on millions of images, it’s almost impossible to track every single one and include it effectively in a case.
With the trial set for June 2025, both sides are watching closely to see how these issues will shape the future of copyright in AI.
Conclusion
Landmark cases and regulatory actions across Europe show there are no easy answers - only an ongoing dialogue among lawmakers, tech companies, and creators. The future of generative AI will depend on finding a middle ground that fosters innovation while respecting individual rights.
Lately, DeepSeek has been the target of regulators worldwide, especially in terms of privacy. Read updates on the topic here.
As this conversation unfolds, stay informed. Most likely, topics of AI, copyright, and privacy are already part of your daily or work life.
Here at Consentmo, we love breaking down anything privacy and compliance related into a meaningful read.